Benchmarking Explainability and Interpretabiltiy Methods in Medical Imaging
Project Background
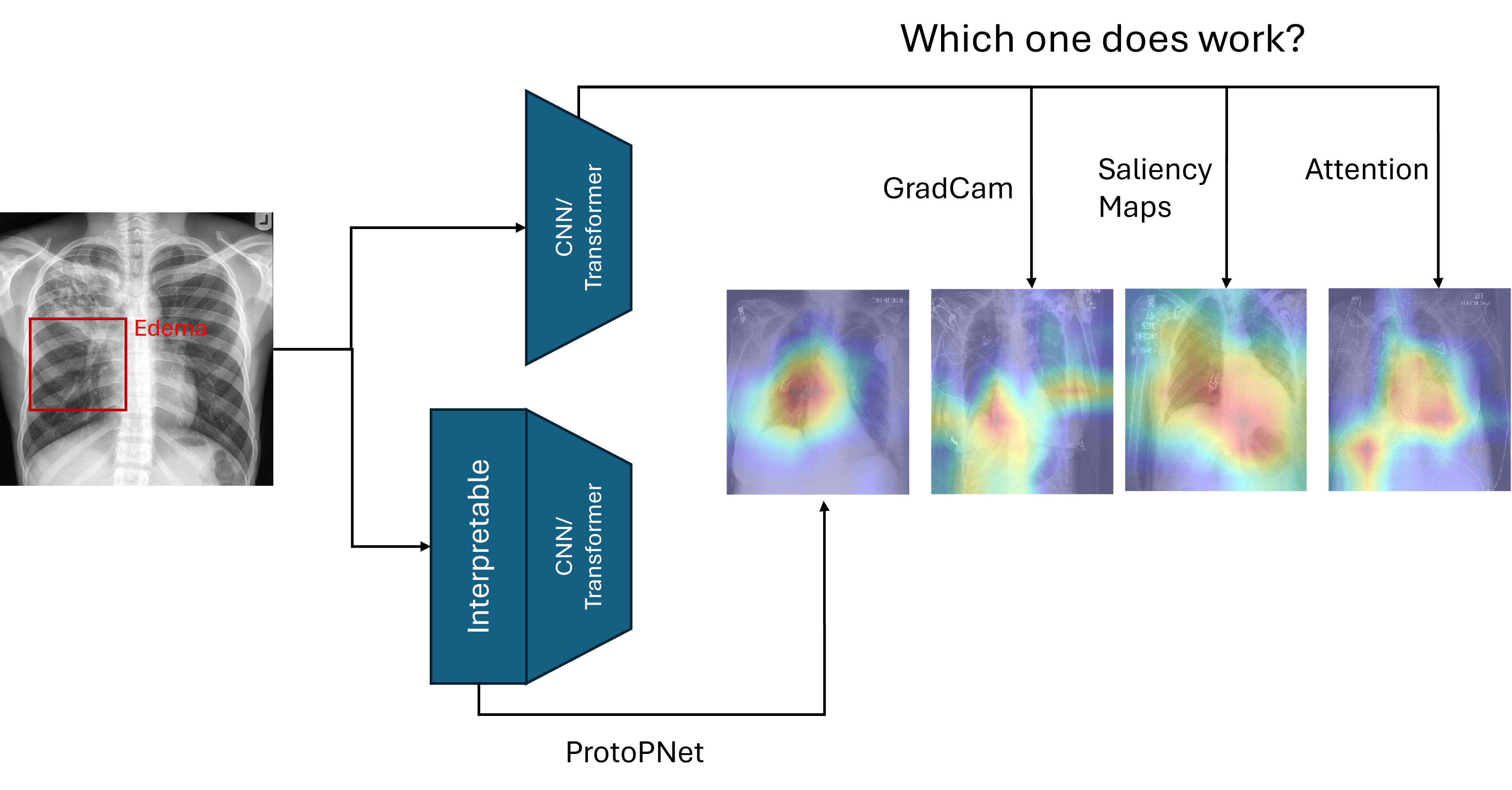
Explainability and interpretability methods are central to making machine learning models more transparent and trustworthy. In computer vision, heatmap-based attribution methods (e.g., Grad-CAM, Integrated Gradients, RISE, ProtoPNet) highlight which regions of an image contribute most to a model’s prediction. For natural images, humans can often intuitively verify whether a heatmap is reasonable (e.g., a dog classifier highlights the dog’s face).
However, in medical imaging, such intuitive validation is rarely possible. Medical decisions require domain expertise, and even small misalignments can correspond to severe diagnostic errors. At the same time, trustworthy AI in medicine is critical for avoiding shortcut learning (e.g., using confounding artifacts instead of relevant anatomy).
We propose to benchmark a range of explainability and interpretability methods on medical imaging datasets by leveraging tasks that provide bounding box annotations. These tasks will be reformulated into classification problems, and the proposed explanations will be evaluated by measuring how well their highlighted regions align with the annotated bounding boxes.
This project will provide a systematic evaluation of explainability and interpretability methods in the context of medical imaging, where reliability and robustness are crucial for clinical trust.
Your Tasks
- Literature Review: Survey explainability and interpretability methods for computer vision, with a focus on their applications in medical imaging.
- Data Preparation: Select medical imaging datasets with bounding box annotations (e.g., chest X-rays, retinal images) and reframe localization tasks as classification tasks.
- Method Implementation: Implement and apply a diverse set of attribution methods, exemplarily:
- Gradient- and activation-based (e.g., Grad-CAM, Integrated Gradients, LRP)
- Perturbation-based (e.g., Occlusion, RISE, SHAP)
- Prototype-based (e.g., ProtoPNet, ProtoTree)
- Attention-based (e.g., ViT attention rollout)
- Evaluation: Quantify explanation quality by comparing attribution heatmaps with bounding box annotations (e.g., Intersection-over-Union, pointing game metrics).
- Analysis: Benchmark methods in terms of faithfulness, robustness, and clinical plausibility. Discuss their suitability for trustworthy AI in medicine.
What We Offer
- Opportunity to contribute to the trustworthy AI in healthcare field with potential for impactful publications.
- Freedom to explore different families of interpretability methods.
- Close supervision and collaboration with researchers in machine learning and medical imaging.
- Access to computational resources including:
- A dedicated GPU cluster (A40/A100 GPUs)
- Large-scale medical imaging datasets
- Tools for experiment tracking and reproducibility
Project Details
Duration: 6 months
Required Background:
- Strong programming skills (Python/PyTorch)
- Understanding of machine learning and computer vision
- Interest in explainable AI and trustworthy ML
- (Preferred) Experience with medical imaging datasets or model evaluation
- Ability to work independently and in interdisciplinary teams
How to Apply
Please send a short motivation statement, your CV, and a recent transcript of records to:
johannes.kaiser@tum.de
References
- Selvaraju, R. R. et al. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. ICCV (2017) https://arxiv.org/abs/2310.16834.
- Petsiuk, V. et al. RISE: Randomized Input Sampling for Explanation of Black-box Models. BMVC (2018) https://arxiv.org/abs/2310.16834.
- Chen, C. et al. This Looks Like That: Deep Learning for Interpretable Image Recognition. NeurIPS (2019) https://arxiv.org/abs/2310.16834.